PCI Express Background
혁신적 그리고 진화적
PCI (1992/1993)
- 혁신적
- Plug and Play jumperless configuration (BARs)
- 전례 없는 대여폭
- 32-bit / 33MHz - 133MB/sec
- 64-bit / 66MHz - 533MB/sec
- Bus-mastering adapter 를 위해 처음부터 설계
- 진화적
- 시스템 BIOS가 장치를 매핑한 다음 운영 체제가 PCI에 대한 추가 지식 없이 부팅되고 실행
- PCI-인식 O/S가 향상된 기능을 얻을 수 있음
- PCI 2.1(1995)은 66MHz 모드로 대역폭을 두 배로 늘림
PCI-X (1999)
- 혁신적
- 전례 없는 대역폭
- 64-bit / 133 MHz 에서 1066MB/sec 까지
- 등록된 버스 포로토콜
- 불할 트랜잭션을 PCI "세계"로 가져옴
- 전례 없는 대역폭
- 진화적
- 하드웨어 및 소프트웨어 level 에서 PCI 호환
- PCI-X 2.0 (2003) 대역폭이 두 배로 증가
- PCI-X 266에서 2133/sec , PCI-X 533 에서 4266MB/sec
PCI Express - 일면 PCIe (2002)
- 혁신적
- 전례 없는 대여폭
- X1 (Width) : 각 방향으로 최대 4GB/sec (PCIe 5.0)
- x16 (Width) : 각 방향으로 최대 64 GB/sec (PCIe 5.0)
- 직렬 버스 아키텍처로 인한 "완화된" 전기적 특성 - 병렬 버스의 동등한 대여폭
- Point-to-point, low voltage, dual simplex with embedded clocking.
(dual simplex : 단방향 통신이 두회전 존재한다는 뜻 즉 Tx 와 Rx 가 따로 있다는 의미)
- Point-to-point, low voltage, dual simplex with embedded clocking.
- 전례 없는 대여폭
- 진화적
- 소프트웨어 수준에서 PCI 호환 - Configuration space, Power Managemnt, etc
- PCI/PCI-X 설계자에게 친숙한 Transaction layer 및 시스템 토폴로지가 PCI/PCI-X와 일치
- 각 세대마다 대역폭이 두 배로 증가 (250MB/sec per lane 에서 부터)
- PCIe 2.0 (2006) 500MB/s/lane
- PCIe 3.0 (2010) ~1GB/s/lane
- PCIe 4.0 (2017) ~2GB/s/lane
- PCIe 5.0 (2019) ~4GB/s/lane
- PCIe 6.0 (2021) 8GB/s/lane
- PCIe 7.0 (2025?) 16GB/s/lane
Address Spaces - Memory & I/O
- CPU semantics 에 깔끔하게 매핑된 Address Space
- 초기 32-bit 주소 공간
- Dual-Address Cycles(DAC)를 통해 도입된 64비트
- PCI/PCI-X에서 address time 의 extra clock
- PCI Express에서 4 DWORD header (vs 3 DWORD)
- CPU semantics 에 깔끔하게 매핑된 IO 공간
- 32-bits 주소 공간
- 사실상 당시 CPU보다 훨씬 큰 주소 공간 이었음
- 버스트 불가능 (Non-burstable)
- 대부분의 PCI 구현에서 지원하지 않음
- PCI-X 체계화
- PCI Express로 이어짐
- Configuration space ???
- Bus / Device / Function (BDF) 은 계층 기반 주소를 형성
- PCIe 3.0+는 이를 "Routing ID" 라고 부르고, "Requester ID" 와 "Completer ID"로 사용함
- 대체 라우팅 식별자(ARI)는 Bus / Function 으로 재정의
- "Function"은 하나의 물리적 Device 에서 여러 개의 독립적인 논리적 에이전트를 허용
( Function 는 논리적으로 여러개로 나눌 수 있다.)- 예: SCSI+ 이더넷 장치의 조합
- Device 당 256바이트 또는 4K 바이트의 configuration space 공간
- PCI/PCI-X 브리지는 계층을 형성
- PCIe 스위치는 계층을 형성
- 소프트웨어에 PCI-PCI 브리지처럼 보임
- 충돌 없이 Device의 주소 decode 를 제어할 수 있음
- 어떤 CPU 주소 공간에도 개념적으로 매핑되지 않음
- PCI-X 및 PCIe에 정의된 Memory-based access 메커니즘(ECAM)
- "Type 0" (동일한 bus #) 와 "Type 1" (다른 bus #) configuration cycle 을 통해 주소가 지정됨

- Configuration Space
- 장치 식별 (Device Identification)
- VendorID: PCI-SIG가 할당
- DeviceID: 공급업체가 할당
- Subsystem VendorID: PCI-SIG
- Subsystem DeviceID: 공급업체
- 장치 식별 (Device Identification)
-
- Address control 제어
- 소프트웨어가 BAR를 읽고/쓰면 필요한 메모리 사이즈를 결정하고 적절히 매핑
- 메모리, I/O 및 버스 마스터 활성화
- 기타 bus-oriented 제어
- 장치별 레지스터
- 최신 설계에는 강하게 권장하지 않음
- 구현하는 경우 새로운 DVSEC 기능 사용
- 256B(함수당) 주소 공간 내에 64B의 레지스터로 정의
- PCI-X 및 PCIe 사양을 사용하여 4KB(함두당) 주소 공간으로 확장
- Address control 제어

- Capabilities List
- Linked list
- List 를 따르세요! 주어진 device 에서 주어진 feature 의 고정된 위치를 추정 할 수 없습니다. 또는, 심지어 reset event 에서도
- 오프셋 002Ch에서 정의된 주소에서 발견된 첫번째 요소 ("Capabilities Pointer")
- 관련된 스펙들에 정의된 features:
- PCI Power Management
- PCI-X
- PCI
- PCI 코드 및 ID 할당 스펙에 통합됨
- 관련된 스펙들에 정의된 features:

- Extended Capabilities List
- Linked list - PCI Express 에서 새롭게 추가되었지만 Capabilities List와 유사함
- 포인터 크가기 커지고, 버전 필드가 공식화 되고, Capability ID 필드가 확장됨
- List 를 따르세요! 주어진 device 에서 주어진 feature 의 고정된 위치를 추정 할 수 없습니다 - 또는 reset event 도 마찬가지 입니다.
- List의 첫 번째 항목은 항상 Configuration Space 에서 0100h 위치에 있습니다.
- PCI Express 및 관련된 사양에(예:MR-IOV, SR-IOV) 정의된 feature들
- PCI 코드 및 ID assignment 스펙에 통합됨
- Linked list - PCI Express 에서 새롭게 추가되었지만 Capabilities List와 유사함

- Interuppts
- PCI 는 INTA#, INTB#, INTC#, INTD# 를 도입. 이들 모두를 INTx 라고 함
- Level sensitive
- CPU 인터럽트에서 분리된 Device
- 시스템 제어 INTx 에서 CPU 인터럽트 매핑
- Configuration registers
- Report A/B/C/D
- CPU 인터럽트 번호로 프로그래밍
- PCI Express는 "virtual wire" 메시지를 통해 이를 모방
- Assert_INTx 및 Deassert_INTx
- PCI 는 INTA#, INTB#, INTC#, INTD# 를 도입. 이들 모두를 INTx 라고 함
- What are MSI and MSI-X?
- Memory Write는 이전의 interrupt semantics("INTx" wires/messages) 를 대체합니다.
- PCI 및 PCI-X device는 INTA/B/C/D 를 ssserting 하는 것을 멈추고, PCI Express device 는 sending 을 멈춥니다.
- MSI 는 하나의 변수를 사용한 하나의 어드레스를 이용하는데, 그 변수는 어떤 "vector" 를 asserting 하는지에 대한 정보를 포함하는 값을 담게 됩니다.
- MSI-X는 각 "vector"를 위해 독립적인 address 와 data 쌍의 테이블을 사용합니다.
- Vector 주소/데이터는 운영 체제에서 프로그래밍하고 하드웨어는 제공된 값을 사용합니다.
- 인터럽트를 사용하는 PCI Express device 들은 둘중 하나를 구현해야 합니다.
- MSI-X는 일반적으로 가장 유연하기 때문에 선호됩니다.
- 대부분의 장치에서 MSI-X 에 더해 MSI를 구현하는 데 "비용이 많이 들지" 않습니다.
- NOTE: 부팅 장치와 MSI가 아닌 운영 체제를 위한 모든 장치는 일반적으로 적절한 INTx 신호를 계속 지원해야 합니다.!
- PC 세계의 UEFI 펌웨어는 최소한 부팅에 대한 이러한 제한을 제거합니다.
- Memory Write는 이전의 interrupt semantics("INTx" wires/messages) 를 대체합니다.
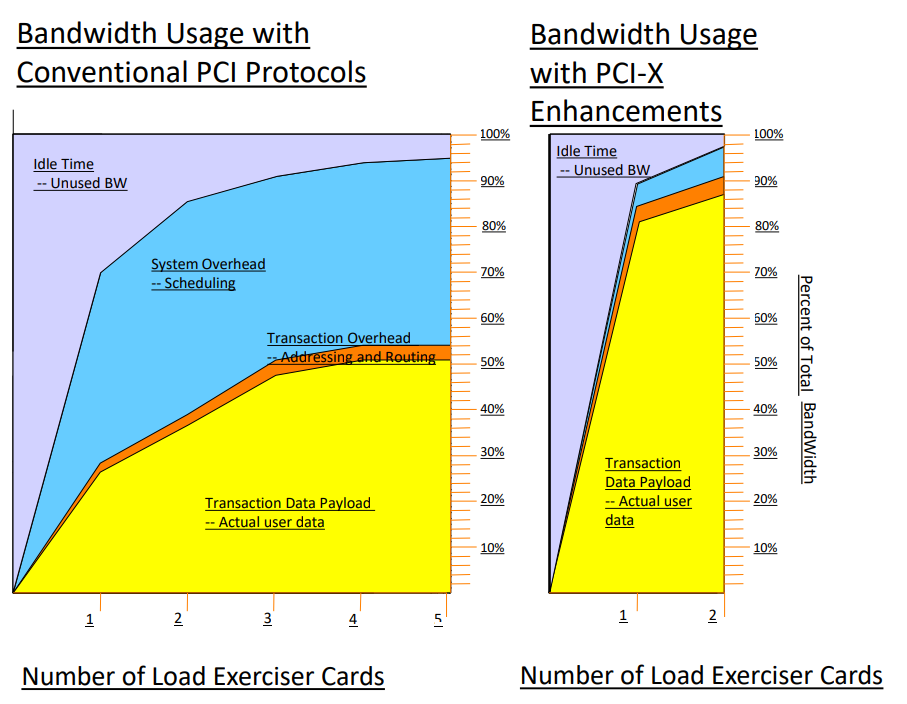
- Split Transactions - 더욱더 효율적인 Read
- PCIe 커맨드는 길이가 포함되어 있지 않으며, 연결이 끊기거나 다시 시도될 수 있습니다.
- 타겟은 즉시 응답하거나 , 가짜 'retry'를 통해 지연된 읽기를 시도 합니다.
- 지연된 읽기 (Delayed Read) : 영리하지만 타겟 장치는 사전에 읽을 데이터의 양을 추측해야 했습니다
- 타겟은 즉시 응답하거나 , 가짜 'retry'를 통해 지연된 읽기를 시도 합니다.
- PCI-X 커맨드는 길이와 시작자의 라우팅 ID를 추가했습니다.
- 명시적인 "나는 데이터를 가지고 너를 다시 방문할께" 응답을 보냄
- 읽기: Pre-fetch(데이터 미리 읽기)가 이제 결정적이 되었습니다
- Pre-fetch 중 발생하는 일련의 가짜 재시도를 제거함으로써 버스 효율이 향상되었습니다
- . ID에 의한 명시적인 완료 라우팅 ( 이는 데이터 전송 또는 명령 완료 과정에서 특정 ID를 사용하여 명확하게 경로를 지정하고 완료 상태를 전달한다는 의미입니다.)
- PCIe 커맨드는 길이가 포함되어 있지 않으며, 연결이 끊기거나 다시 시도될 수 있습니다.
PCI Express Basics
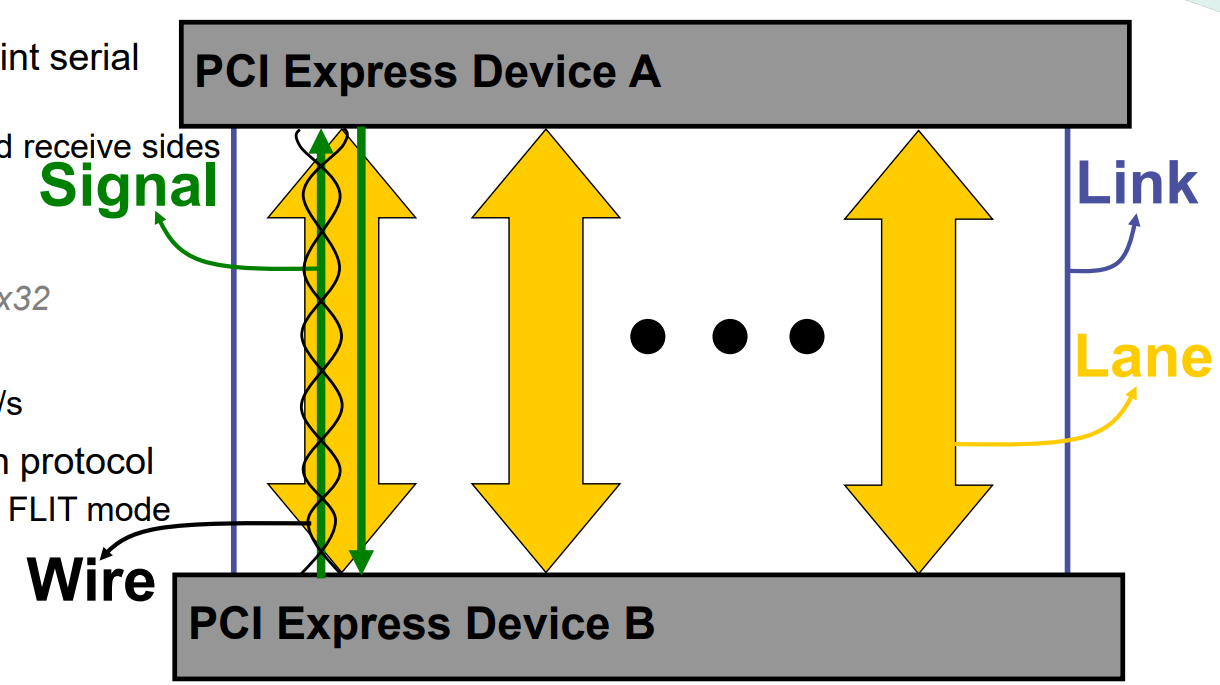
- PCI Express Features & Terminology
- Dual Simplex point-to-point serial connection
- 송신 측과 수신 측이 독립적으로 동작
- 송신(TX)과 수신(RX)이 일치함 ( 이는 데이터 통신에서 송신과 수신 간의 동작이나 타이밍이 서로 맞춰져 있다는 의미입니다.)
- 확장 가능한 Link Widths
- x1, x2, x4, x8, x12, x16, x32
- 확장 가능한 Link Speeds
- 2.5, 5.0, 8, 16, 32, 64GT/s
- Packet based transaction protocol
- PCIe 6.0 introduces new FLIT mode
- 여기서 FLIT(Flow Control Unit)은 데이터 전송의 기본 단위로, PCIe 6.0에서 데이터 전송 효율을 높이기 위해 새롭게 도입된 전송 방식을 의미합니다.
- PCIe 6.0 introduces new FLIT mode
- Dual Simplex point-to-point serial connection
- Upstream/Downstream
- 루트 기준으로 – 위(up)는 루트 쪽으로, 아래(down)는 루트에서 멀어지는 방향
- "디바이스의 '스트림 특성'과 그 포트의 특성을 주의하세요 ("streamness"는 지속적이고 연속적인 데이터 흐름과 관련된 특성을 나타냄)
- device 위에 서있는 그렘린의 관점에서의 방향 ..(즉 Endpoint 입장에서 위쪽은 Upstream Port, 이고 RC 입장에서 아래쪽은 downstream port)

- PCI Express Throughput
- 이 숫자들의 유도 과정
- 1.x 및 2.x 버전에서 8b/10b 인코딩으로 인한 20% 오버헤드
- 참고: 8GT/s에서 32GT/s 값에는 반영되지 않은 128/130 인코딩으로 인한 약 1.5%의 오버헤드
- 이 숫자들의 유도 과정

- 추가 기능들
- 데이터 무결성과 오류 처리( Data Integrity and Error Handling ): 데이터가 전송 중 변조되지 않고 무결하게 전송되도록 하는 기능과 오류 발생 시 이를 처리하는 메커니즘을 가리킵니다.
- 링크 레벨 "LCRC" (Link Cyclic Redundancy Check): 링크 수준에서 발생할 수 있는 데이터 오류를 감지하고 수정하기 위한 검증 메커니즘입니다.
- 링크 레벨 "ACK/NAK" (Acknowledgment/Negative Acknowledgment): 데이터 전송에 대한 확인 응답 또는 부정 응답을 통해 전송의 성공 또는 실패를 알리는 메커니즘입니다.
- 엔드-투-엔드 "ECRC" (End-to-End Cyclic Redundancy Check): 데이터의 시작부터 끝까지 전체 경로에서 무결성을 확인하기 위한 검증 방법으로, 데이터의 신뢰성을 보장합니다.
- 신용 기반 흐름 제어( Credit-based Flow Control ): 데이터 전송 시 시스템 자원의 가용성에 따라 전송을 제어하는 메커니즘으로, 데이터를 보내기 전에 수신 측의 처리 능력을 확인합니다.
- No retry as in PC
- MSI/MSI-X 방식 인터럽트 처리( MSI/MSI-X style interrupt handling) : Message Signaled Interrupts (MSI) 및 그 확장 버전인 MSI-X를 통해 인터럽트 처리를 수행하는 방식으로, 기존 방식보다 더 효율적인 인터럽트 처리와 확장성을 제공합니다.
- 기존 PCI 인터럽트 처리도 인-밴드 방식으로 지원( Also supports legacy PCI interrupt handling in-band): 최신 인터럽트 처리 방식 외에도 기존의 PCI 인터럽트 처리 방식을 인-밴드로 지원하여 호환성을 유지합니다.
- 고급 전력 관리( Advanced power management ): 시스템의 전력 사용을 최적화하고 전력 소비를 줄이기 위한 다양한 전력 관리 기능을 포함합니다.
- 활성 상태 전력 관리 (Active State Power Management): 시스템이 활성 상태일 때도 전력 소비를 줄이는 기술로, 다양한 전력 절감 상태를 지원합니다.
- PCI 호환 전력 관리: 기존 PCI의 전력 관리 기능과 호환되도록 설계된 전력 관리 방식입니다.
- 점진적인 PCI 호환 소프트웨어 모델( Evolutionary PCI-compatible software model ): PCIe가 기존 PCI 소프트웨어 모델과 호환되면서도 새로운 기능을 점진적으로 제공할 수 있도록 설계되어 있다는 것을 의미합니다.
- 데이터 무결성과 오류 처리( Data Integrity and Error Handling ): 데이터가 전송 중 변조되지 않고 무결하게 전송되도록 하는 기능과 오류 발생 시 이를 처리하는 메커니즘을 가리킵니다.
- PCI Express Topology - PCIe(Peripheral Component Interconnect Express) 기술을 기반으로 한 시스템 구조와 연결 방식을 의미합니다.
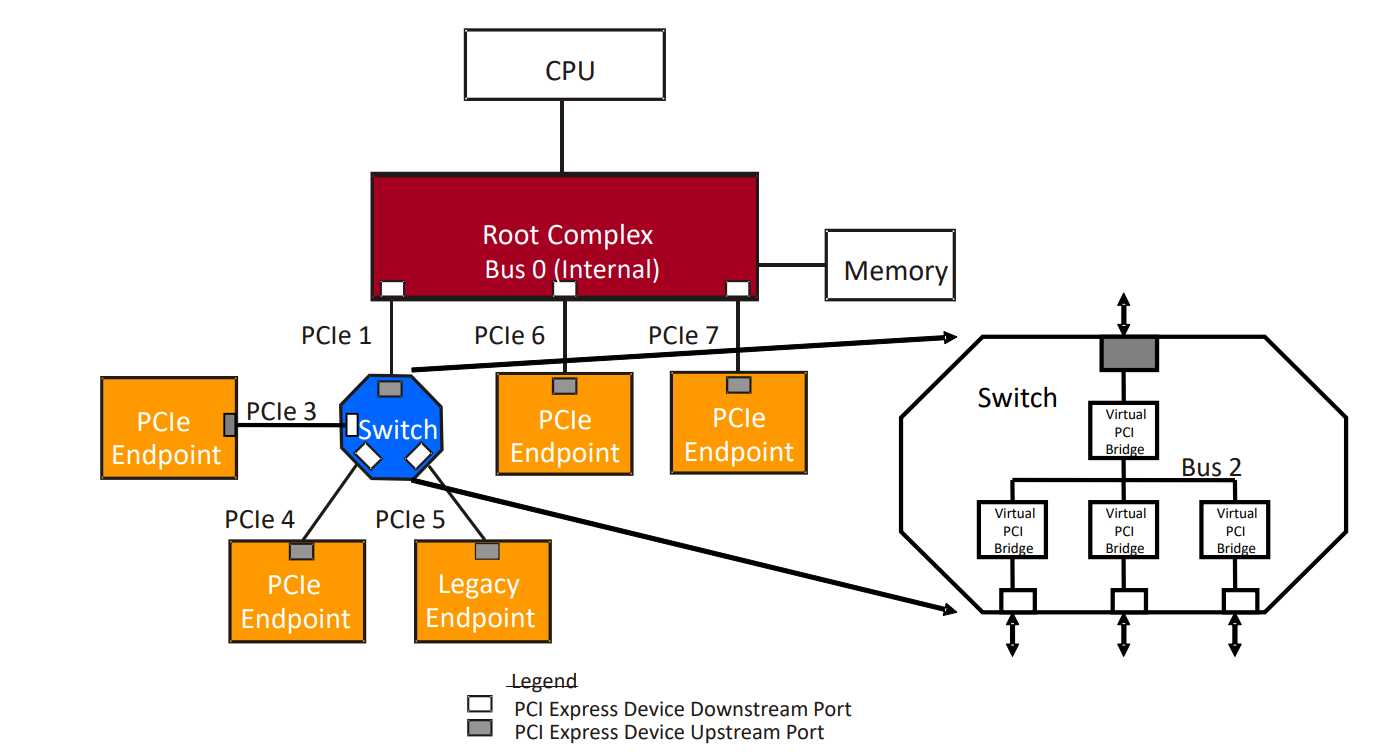
- 전송 타입 그리고 어드레싱
- Packets Route by One of Three Mechanisms
- Address Routing - "전통적인" 메모리와 I/O 요청을 위한 방식: 패킷은 메모리나 I/O 공간 내의 특정 주소를 기반으로 라우팅됩니다. 이 방법은 주로 메모리와 I/O 읽기/쓰기 트랜잭션을 처리할 때 사용됩니다.
- ID Routing - 구성 공간과 완료(Completion)를 위한 라우팅: 장치 식별자(ID)에 따라 패킷이 라우팅됩니다. 주로 PCIe 장치의 구성(configuration) 공간 접근이나 트랜잭션 완료 메시지에 사용됩니다.
- Implicit Routing - PCIe 메시지 전용 라우팅 방식: 새로운 방식으로, 메시지가 루트(Root) 또는 링크 파트너(Link Partner) 등 특정 대상에게 전송될 때 사용됩니다. 이는 주소나 ID가 아닌 고정된 라우팅 경로를 따릅니다.
- Four Transaction Layer Types
- Memory - 메모리 공간 내 데이터 전송을 위한 트랜잭션
- Memory Read Requests (읽기 요청): 데이터가 읽힐 때 Non-Posted 방식으로 전송됩니다. 즉, 데이터 응답을 기다리며 요청이 완료된다는 응답이 필요합니다.
- Memory Write Requests (쓰기 요청): 데이터가 기록될 때 Posted 방식으로 전송됩니다. 즉, 쓰기 요청이 보내진 후 응답을 기다리지 않고 바로 완료됩니다.
- I/O - I/O 공간 접근을 위한 제어 작업 트랜잭션
- I/O Read 및 Write Requests (읽기/쓰기 요청): 모두 Non-Posted 방식입니다. 이는 제어 작업이므로 응답을 기다려야 하며, I/O 읽기 및 쓰기 모두 응답이 필요합니다.
- Configuration - 장치의 제어 및 구성 공간 접근을 위한 트랜잭션
- Configuration Read 및 Write Requests (읽기/쓰기 요청): 구성 공간 접근은 장치 제어를 위한 것이므로 모두 Non-Posted 방식입니다. 응답을 받아야 작업이 완료됩니다.
- Message - 이벤트 신호 및 범용 메시징을 위한 트랜잭션
- 모든 메시지는 Posted 방식으로 전송됩니다. 이는 메시지의 특성상 응답이 필요하지 않고 이벤트나 상태를 통보하는 용도로 사용되기 때문입니다.
- Memory - 메모리 공간 내 데이터 전송을 위한 트랜잭션
- Packets Route by One of Three Mechanisms
- Programmed I/O Transaction

- DMA Transaction

- Peer-to-Peer Transaction
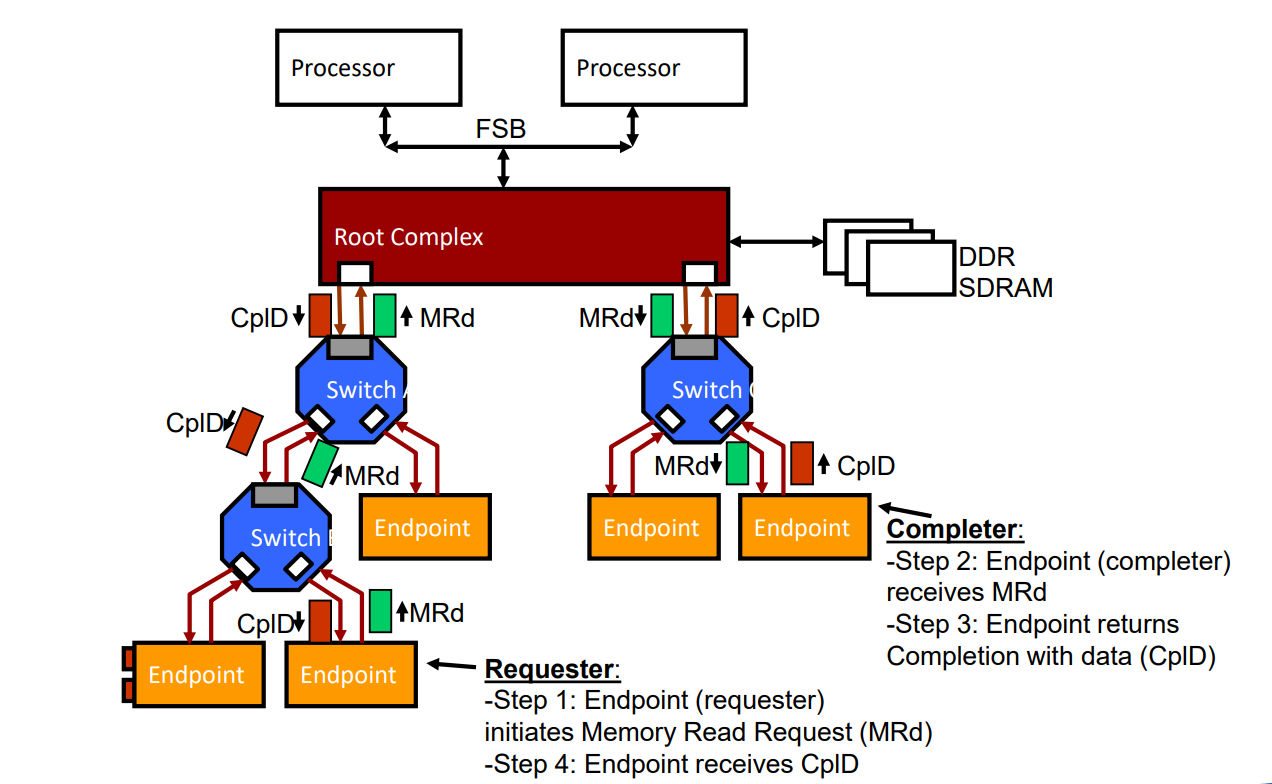
- TLP 의 시작점과 목적지

- TLP 의 구조 (Non-FLIT Mode)

- Flit Mode Overview – New Mode in PCIe 6.0
- 이 내용은 PCIe 6.0에서 도입된 FLIT (Flow Control Unit) Mode에 대한 설명입니다. FLIT Mode는 PCIe에서 높은 데이터 전송 속도를 지원하기 위해 설계된 새로운 데이터 패킷 구조와 전송 방식이며, 64.0 GT/s 이상의 데이터 속도를 지원하는 것이 핵심입니다. 주요 내용을 하나씩 살펴보겠습니다.
- 64.0 GT/s 및 그 이상의 속도를 지원하기 위해 FLIT 모드가 도입되었습니다. 이는 PCIe의 전송 효율을 높이고 더 빠른 데이터 전송을 위해 설계된 새로운 구조입니다.
- FLIT 모드에서는 전통적인 TLP (Transaction Layer Packet) 헤더와 다른 새로운 TLP 헤더를 사용합니다.
- FLIT 모드의 사용 여부는 링크가 초기화될 때 하드웨어에서 자동으로 감지됩니다.
- 한번 협상(negotiation)이 완료되면 모든 데이터 속도에 적용됩니다.
- FLIT 모드와 비-FLIT 모드 간의 링크를 통해 데이터가 전달될 때 TLP 변환이 발생합니다.
- FLIT 크기: 256 바이트 (B)로 고정되어 있습니다. FLIT SIZE = 236B TLP + 6B DLP + 8B CRC + 6B FEC
- 236B TLP (Transaction Layer Packet): 트랜잭션 레이어에서 전송되는 실제 데이터 패킷의 크기입니다.
- 6B DLP (Data Link Layer Packet): 데이터 링크 레이어의 정보로, TLP와 함께 전송되는 메타데이터를 포함합니다.
- 8B CRC (Cyclic Redundancy Check): 오류 검출을 위한 CRC 필드로, TLP와 DLP 전체를 검증하여 데이터 전송 중 오류를 감지합니다.
- 6B FEC (Forward Error Correction): 전방 오류 정정 정보로, 전송 오류를 사전에 감지하고 수정할 수 있는 기능을 제공합니다.
- Interleaved FEC - Interleaved FEC (Forward Error Correction)는 단일 심볼(8비트) 오류를 정정할 수 있습니다. 이는 FLIT 내의 모든 데이터(TLP 바이트, DLP, CRC)를 검증 및 수정할 수 있도록 하여 데이터 전송의 안정성을 높입니다.
- 8B CRC - 8 바이트의 CRC 필드는 전체 250바이트(TLP 및 DLP)를 커버합니다.
- 간소화된 패킷 구조 - FLIT 모드에서는 기존 TLP 구조와 달리 Sync Header, Framing Token, TLP/DLLP CRC가 없습니다. 이는 **TLP의 재포맷(TLP Reformat)**으로 인해 필요한 오버헤드를 줄이고, FLIT을 통한 전송 효율을 높이기 위한 설계입니다.
- 보장된 ACK (Acknowledgment) 및 크레딧 교환 - 메커니즘을 사용하여 데이터 전송의 신뢰성을 보장합니다.
- Per-TLP Framing Overhead Becomes Per-Flit Overhead
- 기존의 TLP마다 발생하던 프레이밍 오버헤드가 이제 FLIT 단위로 전환됩니다.
- 과거에는 각 TLP 패킷이 독립적으로 오버헤드(예: 헤더, CRC 등)를 갖고 전송되 었지만, FLIT 모드에서는 이러한 오버헤드가 FLIT 단위로 묶여서 처리됩니다.
- 즉, 여러 TLP가 하나의 FLIT으로 결합되므로 오버헤드가 FLIT 전체로 통합됩니다.
- Small Packets Are Now More Efficient
- **작은 패킷(데이터량이 적은 패킷)**의 경우, 기존의 TLP 구조에서는 각 TLP마다 오버헤드가 붙었기 때문에 전송 효율이 낮았습니다.
- 그러나 FLIT 모드에서는 FLIT 단위의 오버헤드로 전환되어 여러 TLP를 하나의 FLIT에 담아 전송하므로, 작은 패킷들이 FLIT에 결합되면서 오버헤드 비율이 줄어듭니다.
- 결과적으로 작은 패킷의 전송 효율이 향상됩니다.
- Large Packets Are Now Less Efficient
- 반면에 큰 패킷(데이터량이 많은 패킷)의 경우, 기존의 TLP 구조에서는 큰 패킷이 전송될 때 오버헤드의 비율이 상대적으로 작았기 때문에 효율이 높았습니다.
- 그러나 FLIT 모드에서는 FLIT의 크기가 256 바이트로 고정되어 있기 때문에 큰 패킷이 여러 개의 FLIT으로 나뉘어 전송되어야 합니다.
- 이로 인해 각 FLIT마다 오버헤드가 발생하게 되고, 결과적으로 큰 패킷의 전송 효율이 감소하게 됩니다.
- 기존의 TLP마다 발생하던 프레이밍 오버헤드가 이제 FLIT 단위로 전환됩니다.
- TLP Structure - Flit vs Non-Flit

- DLLP Origin and Destination

- DLLP Structure (Non-FLIT Mode)

- Data Link Layer Payload (DLP) in FLIT Mode
- 각 FLIT DLP를 위해 8 바이트를 할애 했다.
- 첫 번째 2바이트: FLIT 신뢰성 정보
- Ack/Nak/Retry - 지연 최적화
- 이 필드를 통해 각 FLIT에 대한 전송 확인 및 오류 상태를 전달하며, 이를 통해 오류 발생 시 빠른 재전송을 가능하게 하고 전송 지연을 최소화합니다.
- 10비트 시퀀스 넘버 – 저지연 Ack/Nak
- DLP의 첫 번째 2바이트 중 일부는 10비트 시퀀스 번호로 사용됩니다.
- 시퀀스 번호를 통해 패킷의 순서를 유지하고, 전송 중 손실되거나 오류가 발생한 FLIT을 빠르게 식별할 수 있습니다.
- 이전 FLIT의 NOP TLP: 오류 시 재전송 방지
- DLP는 FLIT 전송의 신뢰성을 유지하기 위해 이전 FLIT의 NOP (No Operation) TLP를 처리합니다.
- 이 메커니즘은 에러 발생 시 재전송을 피하는 것을 목적으로 합니다. 즉, 이전에 이미 전송된 FLIT이 오류 없이 정상적으로 도착했다는 정보를 확인하여, 불필요한 재전송이 발생하지 않도록 합니다.
- 이를 통해 전송 효율을 높이고, 오류 발생 시 시스템 지연을 줄입니다.
- Ack/Nak/Retry - 지연 최적화
- 4바이트 DLLP 페이로드
- 표준 DLLP 페이로드 (PCIe 5.0과 유사)
- DLLP는 흐름 제어 크레딧을 전송하고 오류 검출 및 상태 정보를 전달하는 역할을 수행합니다.
- 성능에 중요한 크레딧 최적화 (Optimized Performance Critical Credits)
- NP Hdr, P Hdr, P Data에 대한 크레딧은 2개의 DLLP에 해당합니다
- NP Hdr (Non-Posted Header Credits): 응답을 기다리지 않고 보내는 비게시형 패킷의 헤더 크레딧입니다.
- P Hdr (Posted Header Credits): 응답이 필요 없는 게시형 패킷의 헤더 크레딧입니다.
- P Data (Posted Data Credits): 게시형 데이터의 크레딧으로, 실제 데이터 전송에 필요한 버퍼 여유량을 나타냅니다.
- NP Hdr, P Hdr, P Data에 대한 크레딧은 2개의 DLLP에 해당합니다
- 표준 DLLP 페이로드 (PCIe 5.0과 유사)
- 3개의 DLLP 기능을 FLIT 내에 결합
- 1 DLLP - Ack (Acknowledgment): 이전에 전송된 데이터 패킷의 성공적인 수신을 확인하고 알리는 역할을 담당합니다.
- 2 DLLPs - Credits (P/NP): 흐름 제어를 관리하는 크레딧 정보를 전달합니다.
- P Credits (Posted Credits): 응답이 필요하지 않은 전송 데이터의 크레딧을 관리합니다.
- NP Credits (Non-Posted Credits): 응답이 필요하고 데이터를 수신 측에서 기다리는 형태의 전송에 대한 크레딧을 관리합니다.
- DLP는 재전송되지 않는다. 이는 이전의 DLLP와 동일하다.
- DLP의 재전송 방지
- DLP (Data Link Layer Payload)는 FLIT 모드에서 데이터 링크 계층의 제어 정보를 담는 부분이지만, 재전송(Replay)이 수행되지 않습니다.
- 이는 기존 PCIe 버전에서 사용되는 DLLP (Data Link Layer Packet)와 동일한 동작 방식입니다. PCIe의 데이터 전송 메커니즘에서, DLLP도 재전송이 발생하지 않는 패킷이었습니다.
- 왜 DLP는 재전송되지 않는가?
- DLP와 DLLP는 모두 제어 정보를 전송하며, 이는 흐름 제어나 Ack/Nak 등의 정보를 포함합니다. 만약 DLP 또는 DLLP가 손실되거나 오류가 발생하더라도, 그 정보는 차후의 새로운 패킷에서 다시 제공되기 때문에 재전송이 필요하지 않습니다.
- DLP의 재전송 방지

- Ordered-Set의 출발지와 목적지
- Ordered-Set은 특별한 유형의 짧은 제어 심볼 시퀀스이며, 데이터 패킷(TLP/DLLP)이 아닌, 링크 제어 및 동기화를 위한 신호입니다.

- Ordered-Set 의 구조 (Non-FLIT Mode)

- FLIT Mode 에서 Ordered-Sets
- 64GT/s OS 동작: 반복 및 핸드셰이크 사용
- 비-FLIT 모드보다 더 복잡한 규칙과 다양한 형식
- FLIT 사이에 전송되는 Ordered-Set
- Ordered-Set은 FLIT 사이에 전송됩니다. 이는 데이터 패킷 전송의 제어 및 동기화를 위해 TLP나 DLLP의 데이터 전송과는 별도로 전송되는 것을 의미합니다.
- 수신 측에서 OS와 FLIT의 구분이 가능
- 이는 PHY 계층에서의 구분을 통해 Ordered-Set이 올바르게 식별되고 적절하게 처리될 수 있도록 보장합니다.
- See PHY Logical presentation for details!
- PCI Express Flow Control
- 신용 기반 흐름 제어는 포인트-투-포인트 방식으로 동작하며, 엔드-투-엔드 방식이 아닙니다.

- ACK/NAK Protocol Overview
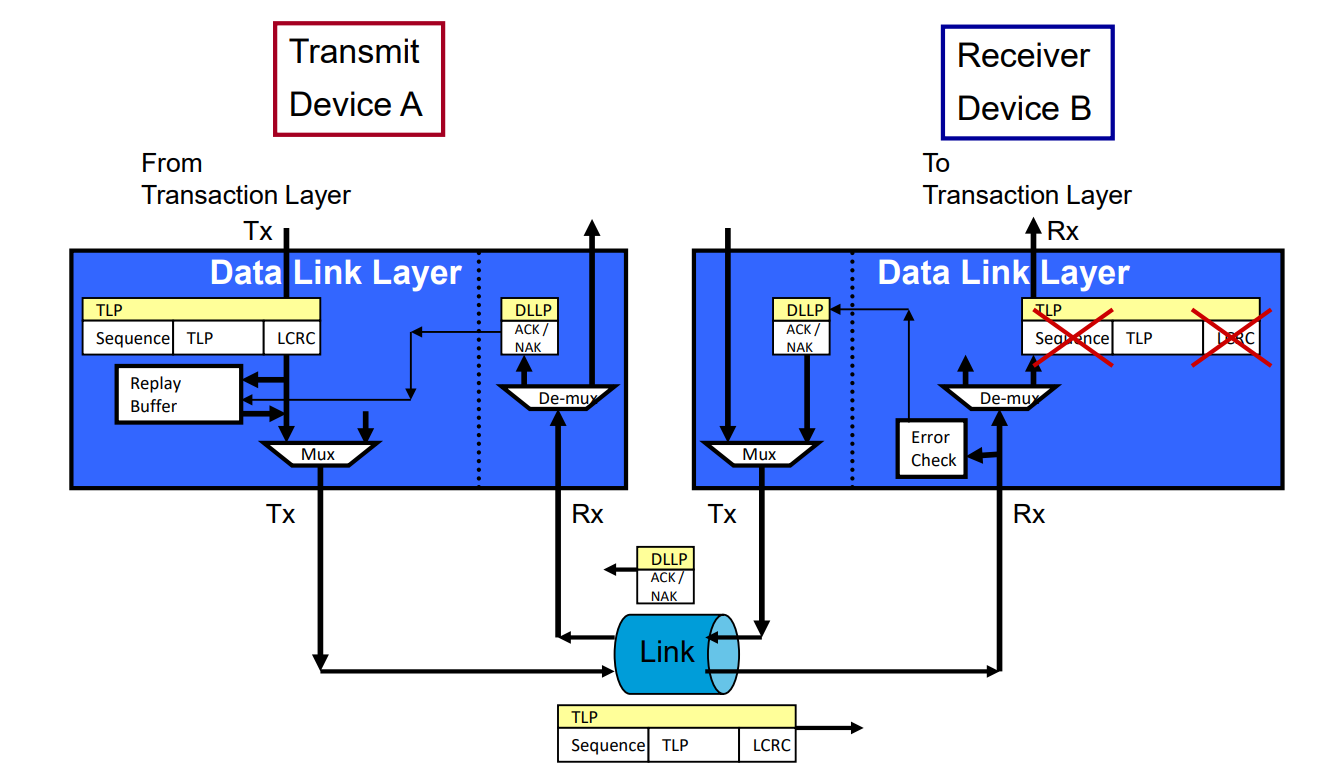
- ACK/NAK 프로토콜 – FLIT 모드에 미치는 영향
- FEC Correction은 오류 검출 전에 수행된다.
- FEC (Forward Error Correction) Correction은 데이터 전송 중 발생하는 오류를 사전에 수정하는 기능을 제공합니다.
- 오류 검출이 수행되기 전에 FEC가 먼저 적용됩니다. 이로써 수신된 데이터의 오류를 먼저 수정하고 나서, 수정이 완료된 데이터에 대해 오류 검출(예: CRC 검증)이 수행됩니다.
- 이렇게 함으로써 오류 검출 전에 오류를 최대한 바로잡아 전송의 신뢰성을 향상시키고, 재전송의 필요성을 줄입니다.
- FLIT CRC 실패 시 재시도(trigger retry)
- FLIT의 CRC (Cyclic Redundancy Check) 검증이 실패하면 재시도(retry)가 발생합니다.
- 이는 기존에 사용되던 LCRC (Link Cyclic Redundancy Check) 실패 시의 처리와 동일하게 동작합니다.
- 즉, FLIT의 전송 데이터가 오류로 인해 검증에 실패하면 해당 FLIT을 재전송하여 무결성을 보장하도록 설계되어 있습니다.
- 최적화: 오류가 발생한 FLIT만 재시도 (Go-Back-N 방식 사용)
- 오류가 발생한 경우, Go-Back-N 재전송 알고리즘을 활용하여 오류가 발생한 FLIT만 재시도하게 됩니다.
- Go-Back-N 방식은 오류가 발견된 FLIT 이후의 모든 FLIT을 다시 보내는 것이 아니라, 오류가 발생한 특정 FLIT만을 재전송합니다.
- 이는 기존 재전송 방식에 비해 더 효율적이며, 필요하지 않은 데이터 재전송을 방지해 전송 지연 및 오버헤드를 줄입니다.
- FEC Correction은 오류 검출 전에 수행된다.

- ECRC Overview
-
End-to-End CRC (ECRC), 흔히 "I Don’t Trust Switches" 기능이라고도 불리
-
TLP의 일부이므로 LCRC에 의해 보호
-
“Invariant” 부분을 보호 (거의 모든 비트)
-
최종 수신자를 위한 것이지만 중간에서 확인할 수 있음
-
스위치는 ECRC 값을 수정하지 않고 그대로 전달 (멀티캐스트 예외)
- FLIT 모드에서 비-FLIT 모드로(또는 그 반대) 변환될 때, 스위치는 ECRC의 오류 검출 기능을 유지해야 합니다. 또는 스위치가 “올바르게 처리해야 함”
-
- PCIe에서 모드나 상태가 일치하지 않는 경우의 동작이 엄격하게 정의되어 있지 않음
- PCIe에서 발생하는 오류를 로그하고 보고하는 방식이 다른 오류와 동일하게 처리되어야 한다
- ECRC(End-to-End Cyclic Redundancy Check)가 올바르지 않은 요청은 "지원되지 않는 요청(UR)" 상태로 응답하는 것이 강력히 권장됩니다.
- PCIe 6.0에서는 FLIT 모드를 구현하는 장치에 대해, **ECRC 오류가 있는 요청에 대해 UR (Unsupported Request) 상태를 반환하는 것이 필수(Must)**라는 규칙을 도입했습니다.
- ECRC가 실패한 패킷을 송신(Tx) 또는 수신(Rx)할 때 크레딧 업데이트를 수행하는 것이 강력히 권장되지만, 필수는 아닙니다.
-
'PCIe' 카테고리의 다른 글
| Lane Margining at the receive (1) | 2024.12.05 |
|---|---|
| DevCon Korea 2024 - PCIe 6.x Electrical Update (4) | 2024.10.08 |
| PCI-SIG Developers Conference Korea 2024 (4) | 2024.09.20 |
| [PCIe] Power Management - 4 - L1 Sub state (1) | 2024.03.12 |
| [PCIe] Power Management - 2 (0) | 2024.01.03 |